容器化的本质(cgroup,namespace,UnionFs)
什么是容器
容器本质上是一种进程隔离的技术。容器为进程提供了一个隔离的环境,容器内的进程无法访问容器外的进程。
为什么说容器本质上是进程,通过执行查看进程树命令(pstree -pa)就可以看出来:
1 | [root@centos7 ~]# pstree -pa |
对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。
- cgroup 的主要作用:管理资源的分配、限制;
- namespace 的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源;
容器和虚拟机区别
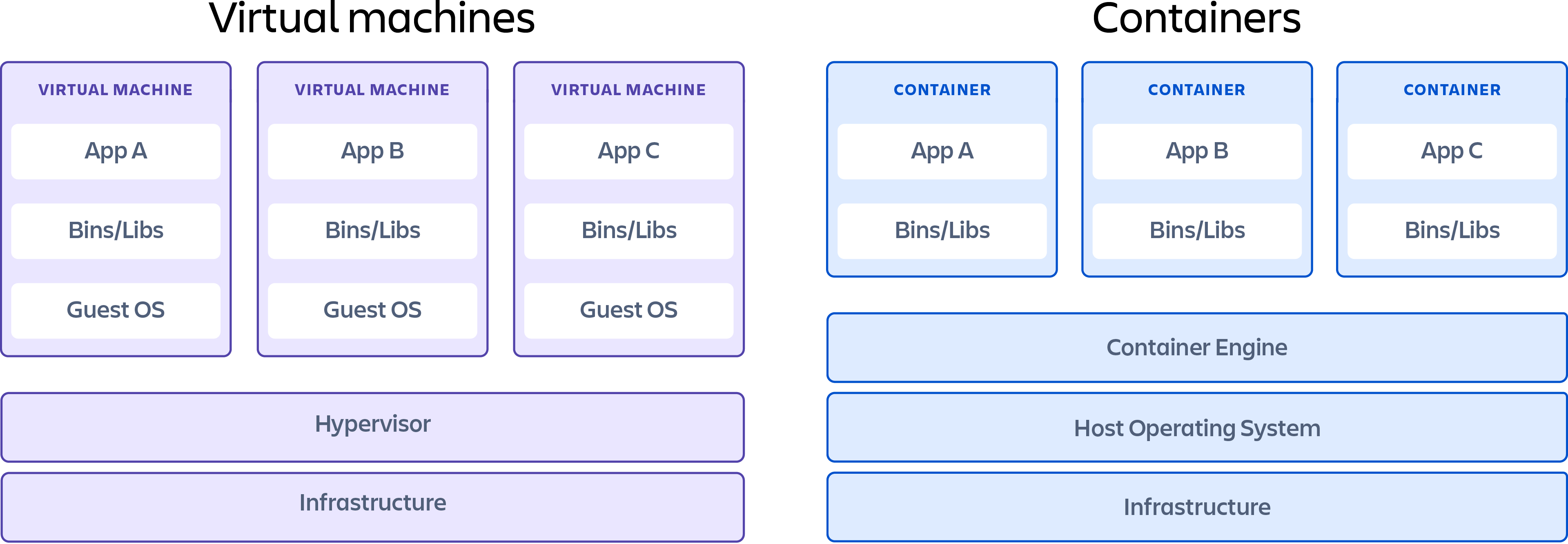
容器和虚拟机之间的主要区别在于,虚拟机将整个计算机虚拟化到硬件层,而容器只虚拟化操作系统级别以上的软件层。
cgroup
简介
cgroups 的全称是control groups,cgroup 主要限制的资源cpu、内存、网络、磁盘I/O,cgroups为每种可以控制的资源定义了一个子系统,可以通过执行cat /proc/cgroups或者ls /sys/fs/cgroup/查看所有支持的子系统。
1 | [root@centos7 ~] cat /proc/cgroups #查看所有支持的subsystem |
实战
cpu-手动限制进程的cpu使用率
这里以cpu子系统来限制进程的cpu使用率进行实战认识,其他子系统也是差不多的原理。
进入到
/sys/fs/cgroup/cpu目录,创建一个container_test目录,会在该目录下自动产生一些文件,这些文件代表cpu资源的各种控制指标。1
2
3
4
5
6
7
8
9
10
11
12[root@centos7 ~]# cd /sys/fs/cgroup/cpu
[root@centos7 cpu]# mkdir container_test
[root@centos7 cpu]# ls
cgroup.clone_children container_test cpu.cfs_period_us cpu.shares release_agent
cgroup.event_control cpuacct.stat cpu.cfs_quota_us cpu.stat system.slice
cgroup.procs cpuacct.usage cpu.rt_period_us kubepods.slice tasks
cgroup.sane_behavior cpuacct.usage_percpu cpu.rt_runtime_us notify_on_release user.slice
[root@centos7 cpu]# cd container_test/
[root@centos7 container_test]# ls
cgroup.clone_children cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us notify_on_release
cgroup.event_control cpuacct.usage cpu.cfs_quota_us cpu.shares tasks
cgroup.procs cpuacct.usage_percpu cpu.rt_period_us cpu.stat创建一个测试脚本,来模拟进程吃掉所有资源,通过
top命令,可以看到sh命令进程cpu使用率已经100%了。1
2
3
4
5[root@centos7 container_test]# cat ~/while.sh
#!/bin/bash
while : ; do : ; done &
[root@centos7 container_test]# sh ~/while.sh
[root@centos7 container_test]# top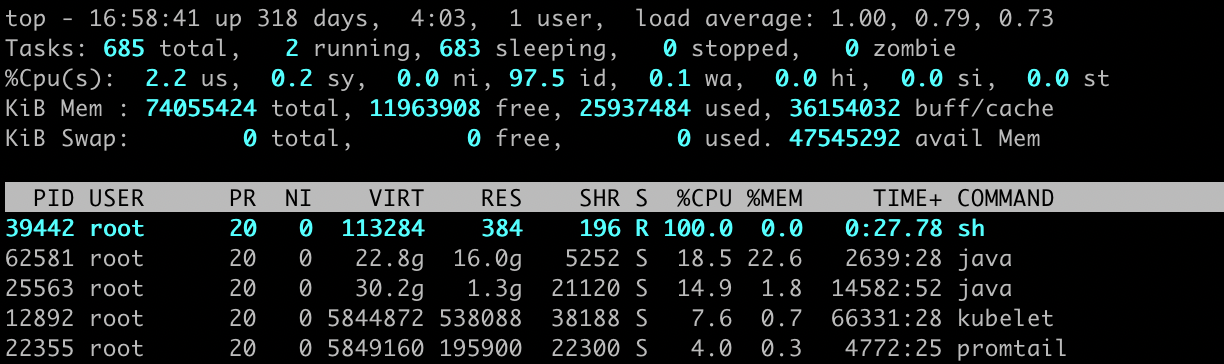
查看
cpu.cfs_quota_us值,默认为-1,代表未限制,cfs_period_us默认为100000us=100ms=0.1s(秒),接下来我们向cpu.cfs_quota_us输入20ms=20000us,cfs_period_us值维持不变还是为100ms,cfs_quota_us表示的是cfs_period_us的周期内,分配20/100的时间,即20%,接下来验证下1
2
3
4
5
6
7[root@centos7 container_test]# cat cpu.cfs_quota_us
-1
[root@centos7 container_test]# cat cpu.cfs_period_us
100000
[root@centos7 container_test]# echo 20000 > cpu.cfs_quota_us //只能用echo进行写入,用vim会提示错误
[root@centos7 container_test]# cat cpu.cfs_quota_us
20000要让cpu限制生效,还需要进行进程id绑定到限制资源里面。
1
2
3[root@centos7 container_test]# echo 39442 > tasks
[root@centos7 container_test]# cat tasks
39442最后执行
top查看cpu使用率,基本在20以下,最后记得结束掉测试程序,删除目录1
2
3
4
5
6
7
8
9
10
11
12
13[root@centos7 container_test]# top
top - 17:29:29 up 318 days, 4:33, 1 user, load average: 1.60, 1.13, 0.97
Tasks: 685 total, 2 running, 683 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.9 us, 0.2 sy, 0.0 ni, 98.7 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 74055424 total, 12164068 free, 25939268 used, 35952088 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 47543512 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
39442 root 20 0 113284 384 192 R 19.8 0.0 0:58.94 sh
[root@centos7 container_test]# kill 39442
[root@centos7 cpu]# rmdir container_test
通过容器ID查看对应的cgroup
知道了cgroup的基本原理,现在就可以来验证k8s的pod是不是通过cgroup来控制的了。
查询容器id
1
2[root@centos7 ~]# docker ps | grep exxk-api
03ee100f264b harbor…/exxk-api "sh -c 'java ${JAVA_…" 4 days ago Up 4 days k8s_springboot-app_exxk-api…}'"根据容器id查询进程PID
1
2
3
4[root@centos7 ~]# docker top 03ee100f264b
UID PID PPID C STIME TTY TIME CMD
root 31270 31245 0 Feb22 ? 00:00:00 sh -c java ${JAVA_OPTS} -jar /app.jar
root 31294 31270 0 Feb22 ? 00:13:44 java -jar /app.jar根据进程PID查询cgroup,可以看到name、memory、hugetlb、blkio…各个subsystem的配置目录,其实都是指向的同一个目录
1
2
3
4
5
6
7
8
9
10
11
12[root@centos7 ~]# cat /proc/31270/cgroup
11:pids:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
10:net_prio,net_cls:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
9:cpuset:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
8:perf_event:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
7:freezer:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
6:cpuacct,cpu:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
5:devices:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
4:blkio:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
3:hugetlb:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
2:memory:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
1:name=systemd:/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope进入到其中一个目录,就能看到该容器的cgroup相关资源配置
1
2
3[root@centos7 ~]# cd /sys/fs/cgroup/cpu//kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8ddb18c0_ed52_4ac3_877c_4c53bac38e1c.slice/docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope
[root@centos7 docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope]# ls
cgroup.clone_children cgroup.event_control cgroup.procs cpuacct.stat cpuacct.usage cpuacct.usage_percpu cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat notify_on_release tasks在关联进程的配置里面可以进一步确定关联了该容器的pid
1
2
3
4
5[root@centos7 docker-03ee100f264b24f13474f82459512670a15815312027345bbecd82fe66ab709f.scope]# cat tasks
31270
31294
31305
...
namespace
简介
容器和虚拟机技术一样,从操作系统级上实现了资源的隔离,它本质上是宿主机上的进程(容器进程),所以资源隔离主要就是指进程资源的隔离。实现资源隔离的核心技术就是 Linux namespace。
隔离意味着可以抽象出多个轻量级的内核(容器进程),这些进程可以充分利用宿主机的资源,宿主机有的资源容器进程都可以享有,但彼此之间是隔离的,同样,不同容器进程之间使用资源也是隔离的,这样,彼此之间进行相同的操作,都不会互相干扰,安全性得到保障。
为了支持这些特性,Linux namespace 实现了 6 项资源隔离,基本上涵盖了一个小型操作系统的运行要素,包括主机名、用户权限、文件系统、网络、进程号、进程间通信。
| Namespace | 隔离内容 |
|---|---|
| ipc | 信号量、消息队列、共享内存 |
| mnt | 挂载点(文件系统) |
| net | 网络设备、网络栈、端口等 |
| pid | 进程编号 |
| user | 用户和用户组 |
| uts | 主机名或域名 |
可以通过执行ls -al /proc/<PID>/ns查看进程的隔离资源
1 | [root@centos7 ~]# ls -al /proc/31245/ns |
Namespace的API由三个系统调用(clone、unshare、setns)和一系列 /proc 文件组成。
- clone() : 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述系统调用参数达到隔离的目的。
- unshare() : 使某进程脱离某个 namespace。
- setns() : 把某进程加入到某个 namespace。
unshare 同名的命令行工具(它实际上是调用了系统调用 unshare)
实战
pid-手动隔离进程的pid
要只能看到自己的pid,让进程看起来像在一个新的系统,这就是pid隔离。
创建pid namespace
在namespace中挂载
proc文件系统说明:如果只是创建pid namespace,不能保证只看到namespace中的进程。因为类似
ps这类系统工具读取的是proc文件系统。proc文件系统没有切换的话,虽然有了pid namespace,但是不能达到我们在这个namespace中只看到属于自己namespace进程的目的。在创建pid namespace的同时,使用--mount-proc选项,会创建新的mount namespace,并自动mount新的proc文件系统。这样,ps就可以看到当前pid namespace里面所有的进程了。因为是新的pid namespace,进程的PID也是从1开始编号。对于pid namespace里面的进程来说,就好像只有自己这些个进程在使用操作系统。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#前两个步骤可以一个命令完成
[root@centos7 ~]# unshare --pid --mount-proc --fork bash
[root@centos7 ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 10:37 pts/0 00:00:00 bash
root 12 1 0 10:37 pts/0 00:00:00 ps -ef
#启动一个新的bash窗口
[root@mh-k8s-worker-247-16 ~]# pstree -pa
systemd,1 --switched-root --system --deserialize 22
├─NetworkManager,1177 --no-daemon
├─sshd,1427 -D
│ ├─sshd,48070
│ │ └─bash,48082
│ │ └─unshare,63281 --pid --mount-proc --fork bash
│ │ └─bash,63282
│ │ └─ping,29347 127.0.0.1
......
[root@centos7 ~]# ps -ef | grep bash
root 63281 48082 0 10:37 pts/0 00:00:00 unshare --pid --mount-proc --fork bash
root 63282 63281 0 10:37 pts/0 00:00:00 bash
#查看新建的namespace,会发现和之前执行这个命令的结果不同,而且只有mnt和pid不同。
[root@centos7 ~]# ls -al /proc/self/ns
总用量 0
dr-x--x--x 2 root root 0 3月 1 14:52 .
dr-xr-xr-x 9 root root 0 3月 1 14:52 ..
lrwxrwxrwx 1 root root 0 3月 1 14:52 ipc -> ipc:[4026531839] #ipc:[4026531839]
lrwxrwxrwx 1 root root 0 3月 1 14:52 mnt -> mnt:[4026534037] #mnt:[4026531840]
lrwxrwxrwx 1 root root 0 3月 1 14:52 net -> net:[4026531956] #net:[4026531956]
lrwxrwxrwx 1 root root 0 3月 1 14:52 pid -> pid:[4026534038] #pid:[4026531836]
lrwxrwxrwx 1 root root 0 3月 1 14:52 user -> user:[4026531837] #user:[4026531837]
lrwxrwxrwx 1 root root 0 3月 1 14:52 uts -> uts:[4026531838] #uts:[4026531838]
#查看挂载信息
[root@centos7 ~]#cat /proc/self/mountinfo | sed 's/ - .*//'从上面的结果可以知道PID= 63281其实和PID=1是同一个进程。
mount-手动隔离进程的文件系统
创建一个根文件系统,利用docker的alpine系统创建
1
2
3
4
5
6
7
8
9[root@centos7 ~]# docker run -it alpine sh
#另开一个bash窗口
[root@centos7 ~]# docker ps | grep alpine
b8824ba694ab alpine "sh" About a minute ago Up About a minute great_mcnulty
[root@centos7 ~]# docker export b8824ba694ab --output=alpine.tar
[root@centos7 ~]# mkdir alpine
[root@centos7 ~]# tar -xf alpine.tar -C alpine
[root@centos7 ~]# ls alpine
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var创建一个容器,
--propagation private是为了容器内部的挂载点都是私有,private 表示既不继承主挂载点中挂载和卸载操作,自身的挂载和卸载操作也不会反向传播到主挂载点中。1
[root@centos7 ~]# unshare --pid --mount --fork --propagation private bash
使用
pivot_root命令,在容器里面更换root目录1
2
3
4
5
6
7
8[root@centos7 ~]# mkdir -p alpine/old_root
[root@centos7 ~]# mount --bind ./alpine/ ./alpine/
[root@centos76 ~]# cd alpine
[root@centos7 alpine]# pivot_root ./ ./old_root/
[root@centos7 alpine]# exec /bin/sh
/ # /bin/ls
bin etc lib mnt opt root sbin sys usr
dev home media old_root proc run srv tmp var额外,可以使用
cat /proc/self/mountinfo | sed 's/ - .*//'命令分析挂载信息。
使用shell命令创建一个简单容器
下面所有建容器的命令,就相当于docker run -it alpine sh命令了
1 | #执行报错,检查max_user_namespaces的值,见常见问题1 |
UnionFs
简介
Docker中还有另一个非常重要的问题需要解决 - 也就是镜像,我们知道镜像是有很多层的,相同的层可以共用,通过拉取(pull)镜像,就能清晰看到。那到底是如何实现的呢?
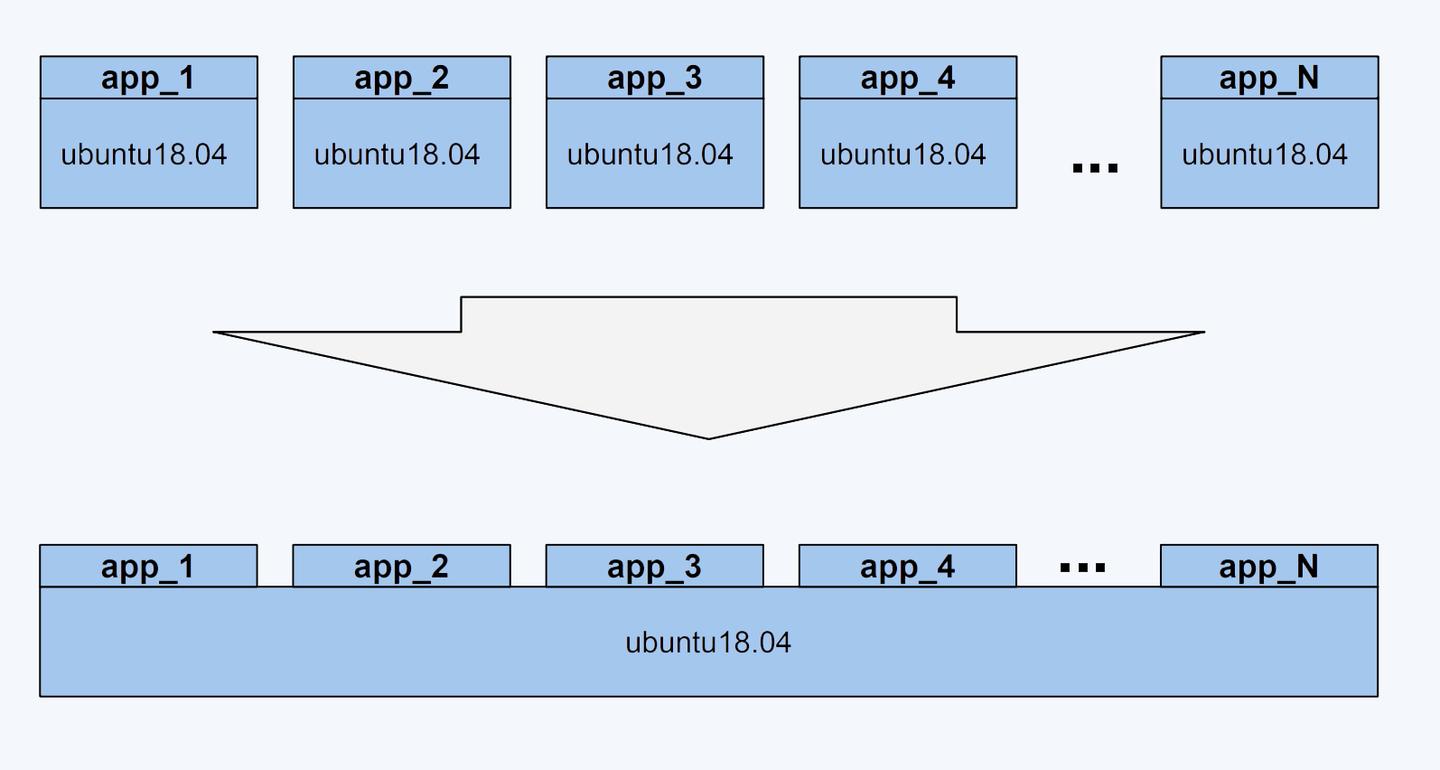
Union File System,简称UnionFS,UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统『联合』到同一个挂载点的文件系统服务。
UnionFS 有很多种,Docker 目前支持的联合文件系统包括 OverlayFS, AUFS, Btrfs, VFS, ZFS 和 Device Mapper,不同版本的Linux使用的UnionFS不同,可以通过执行docker info来查看,例如:
- centos, docker18.03.1-ce:
Storage Driver: overlay2 - debain, docker17.03.2-ce:
Storage Driver: aufs
执行docker inspect <容器id>查看容器的overlay2,可以看到
LowerDir:目录里面的内容是不会被修改的,目录权限是只读的(ro)。MergedDir:挂载目录,合并后的目录,也就是用户看到的目录,用户的实际文件操作在这里进行。UpperDir:目录里的创建,修改,删除操作,都会在这一层反映出来,权限是可读写(rw)。WorkDir:它只是一个存放临时文件的目录,OverlayFS 中如果有文件修改,就会在中间过程中临时存放文件到这里。
1 | [root@centos7 ~]# docker inspect 03ee100f264b |
实战
手动创建overlay
先创建四个目录,写入值,进行区分
1
2
3
4
5[root@centos7 unionfs]# mkdir upper lower merged work
[root@centos7 unionfs]# ls
lower merged upper work
[root@centos7 unionfs]# echo "hello lower" >lower/in_lower.txt
[root@centos7 unionfs]# echo "hello upper" >lower/in_upper.txt挂载一个
overlay类型的目录,挂载成功,发现merged已经融合了lower文件的内容。1
2
3[root@centos7 unionfs]# mount -t overlay overlay -o lowerdir=./lower,upperdir=./upper,workdir=./work/ ./merged
[root@centos7 unionfs]# ls merged/
in_lower.txt in_upper.txt现在修改
merged下面的文件,发现对应的upper会跟着修改,但是lower并不会修改。1
2
3
4
5
6
7
8
9
10[root@centos7 unionfs]# cd merged/
[root@centos7 merged]# echo "change ">> in_lower.txt
[root@centos7 merged]# cat in_lower.txt
hello lower
change
[root@centos7 merged]# cat ../upper/in_lower.txt
hello lower
change
[root@centos7 merged]# cat ../lower/in_lower.txt
hello lower删除
in_lower文件,merged目录下换删除,但是upper目录下还是存在该文件,只是文件文件类型变成了c。1
2
3
4
5[root@centos7 merged]# rm in_lower.txt
rm:是否删除普通文件 "in_lower.txt"?y
[root@centos7 merged]# ll ../upper/
总用量 0
c--------- 1 root root 0, 0 3月 2 14:24 in_lower.txt
常见问题
执行
unshare --user返回unshare: unshare 失败: 无效的参数解决:max_user_namespaces文件记录了允许创建的user namespace数量,有的系统默认是0,执行
echo 2147483647 > /proc/sys/user/max_user_namespaces