Tools-Python3
安装环境准备
直接使用win10的wsl沙盒Ubuntu系统,自带python3.5
安装
1 | apt install python3-pip |
注意事项
IndentationError: unexpected indent 检查缩进是否一致,空格和Tab符号注意区分
实战
通过cookie爬百度数据
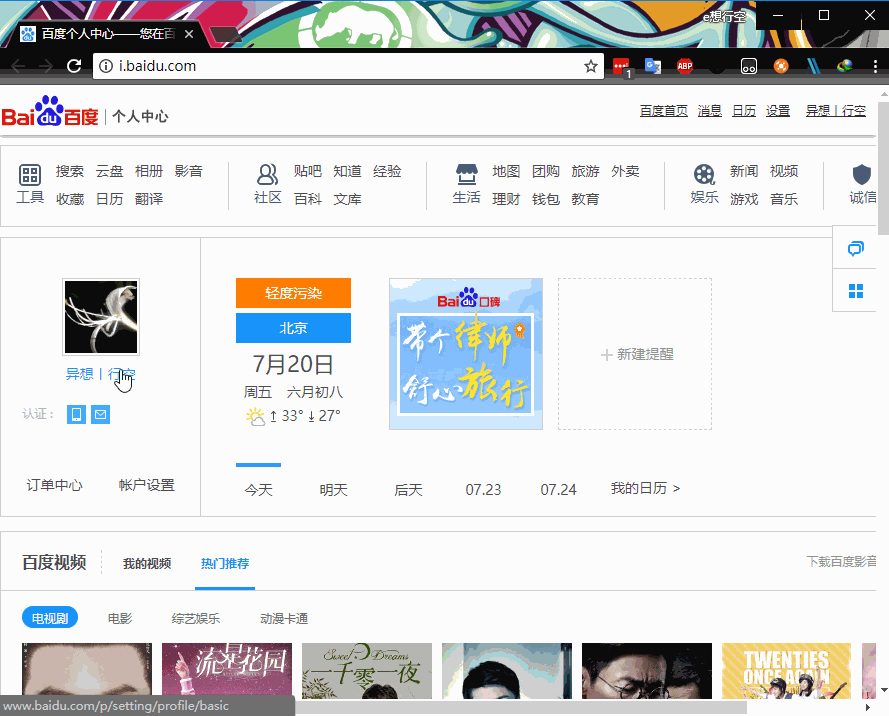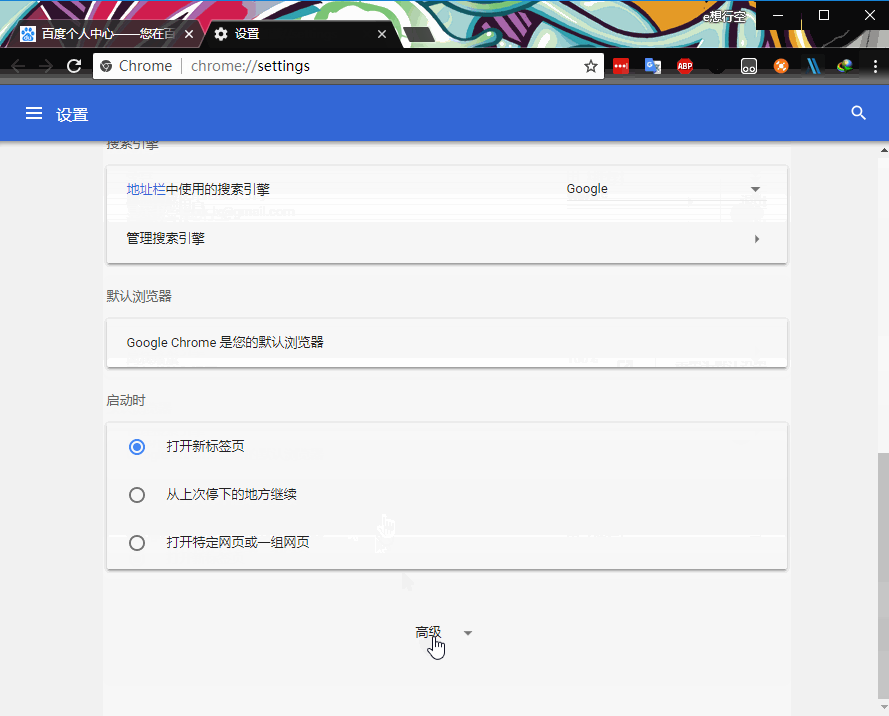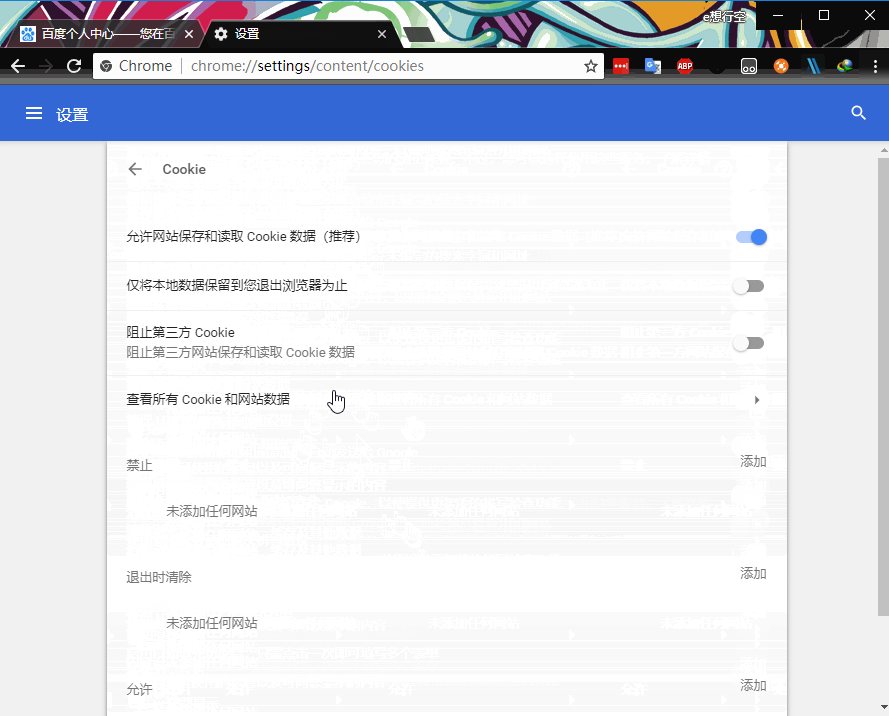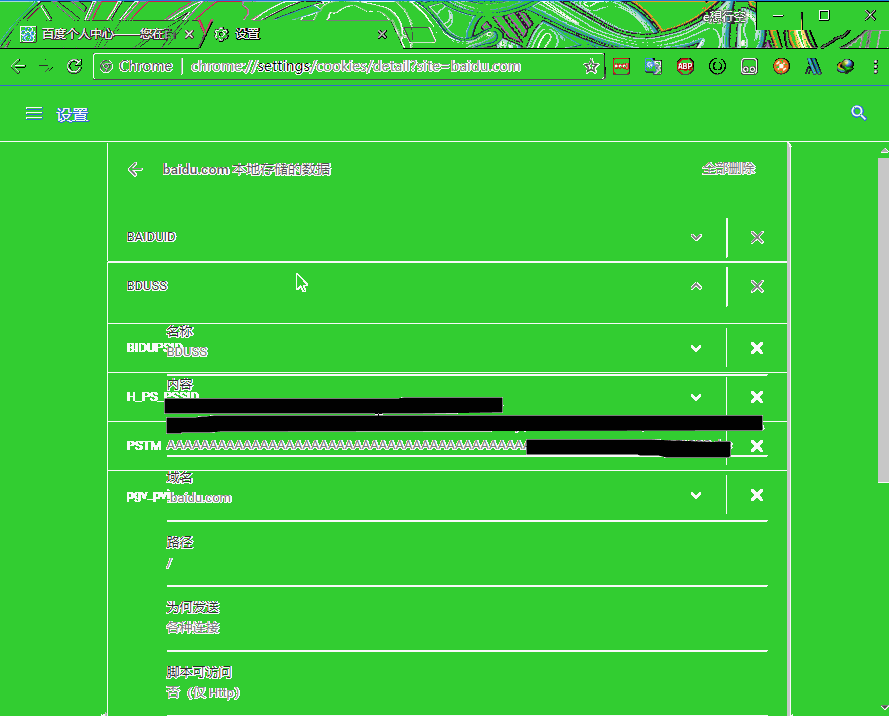
登陆百度,通过浏览器设置-内容管理-cookie,找到百度的BDUSS的内容复制
编写脚本
login.py1
2
3
4
5
6
7
8
9
10
11
12import requests
#需要爬数据的url
url = 'http://i.baidu.com/'
#浏览器访问网站的cookie信息
cookie = {"BDUSS":"----------------------------------------------------AAAAAAAAAAA----------------AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA--"}
#requests请求,获取登录网站页面的内容
html = requests.get(url,cookies=cookie).content
#print(html)
#把内容保存为文件
with open("baidu.html", 'wb') as f:
f.write(html)
f.close()在Ubuntu bash执行
python3 login.py,会生成一个文件baidu.html在当前目录,打开如果能看到个人信息就证明获取成功
爬百度翻页数据
上面已经登陆成功了,下面直接用cookie进行爬数据会被重定向,还需要添加请求头,以及翻页参数
1 | import requests |
最终版爬百度经验的个人经验数据
1 | import requests |